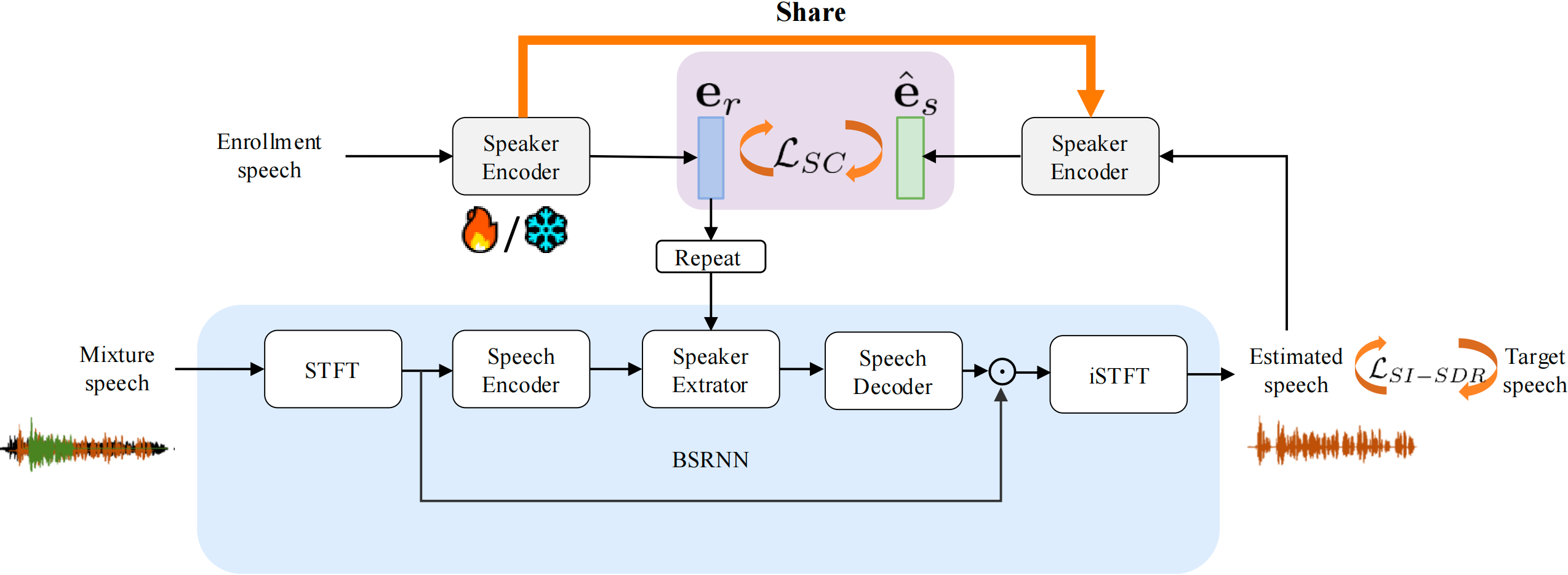
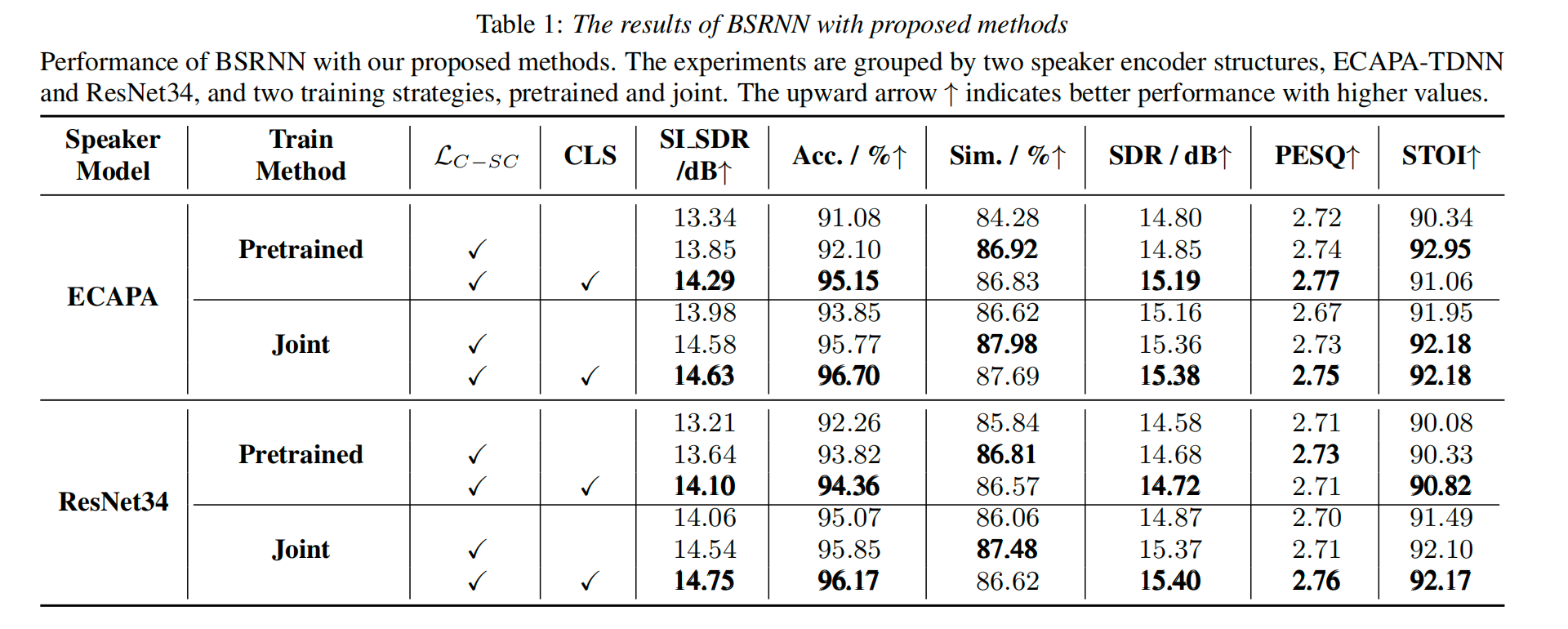
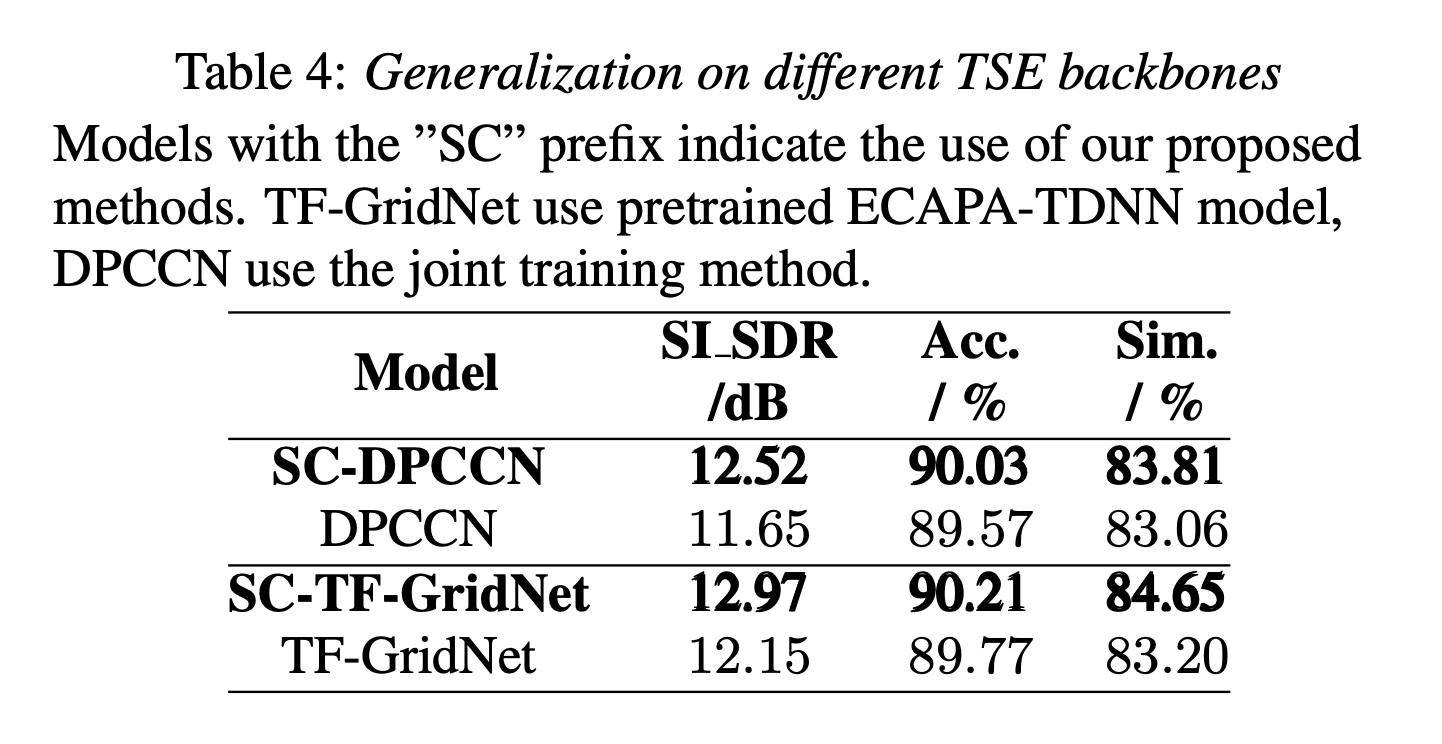
Target Speaker Extraction (TSE) uses a reference cue to extract the target speech from a mixture. In TSE systems relying on audio cues, the speaker embedding from the enrolled speech is crucial to performance. However, these embeddings may suffer from speaker identity confusion. Unlike previous studies that focus on improving speaker embedding extraction, we improve TSE performance from the perspective of speaker consistency. In this paper, we propose a speaker consistency-aware target speaker extraction method that incorporates a centroid-based speaker consistency loss. This approach enhances TSE performance by ensuring speaker consistency between the enrolled and extracted speech. In addition, we integrate conditional loss suppression into the training process. The experimental results validate the effectiveness of our proposed methods in advancing the TSE performance.